Python文件读写
对于Python的文件读写的思维导图和一些代码。
思维导图
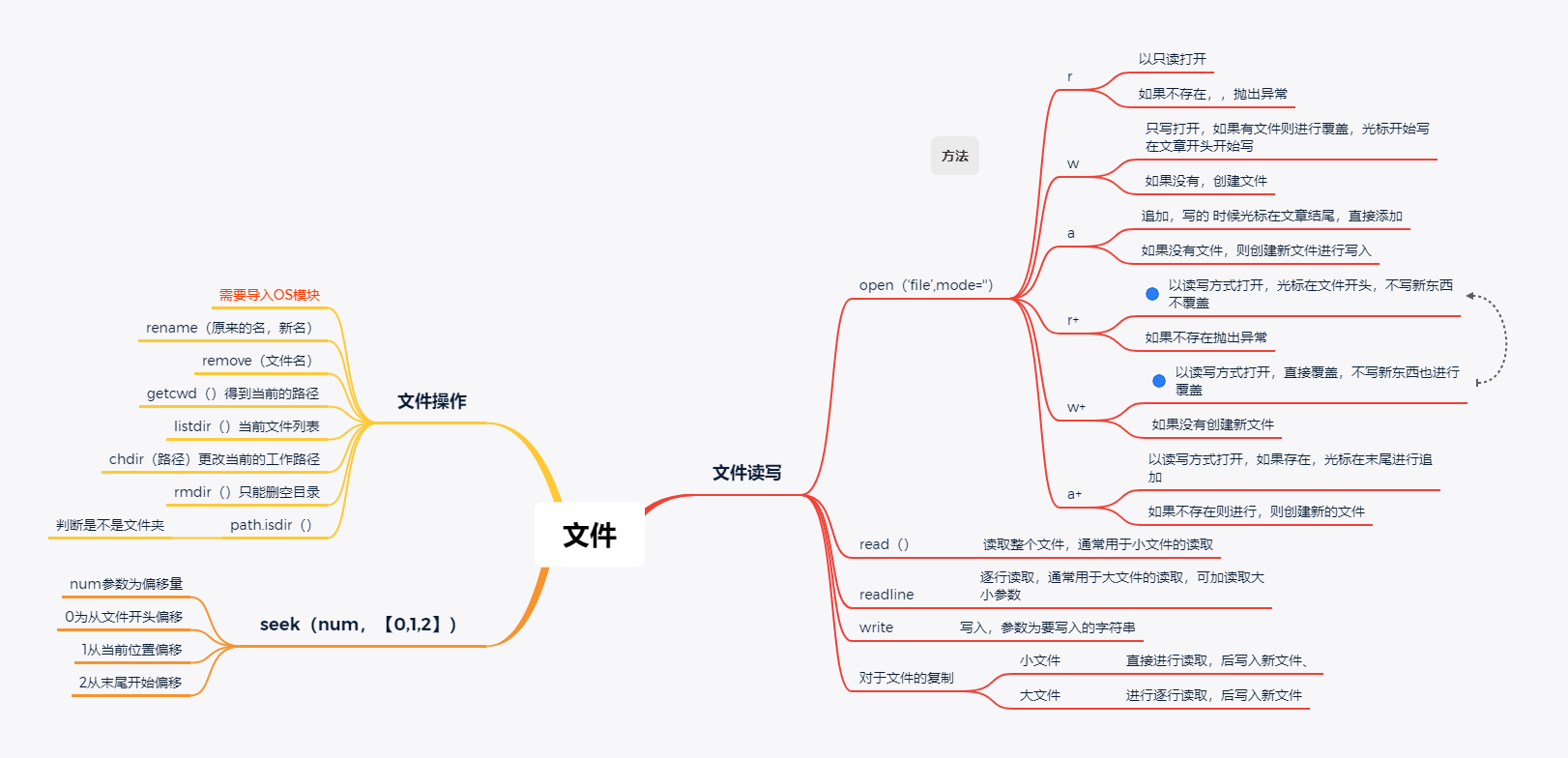
代码
1 | # 读文件夹的深度优先遍历 |
1 | # 用于实现对于大文件的复制 |
1 | # a+ 如果存在则将光标放到最后再写,如果不存在则创建新的再进行写入 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Ongeno's Blog!

对于Python的文件读写的思维导图和一些代码。
1 | # 读文件夹的深度优先遍历 |
1 | # 用于实现对于大文件的复制 |
1 | # a+ 如果存在则将光标放到最后再写,如果不存在则创建新的再进行写入 |








