
第20天的python作业--正则表达式
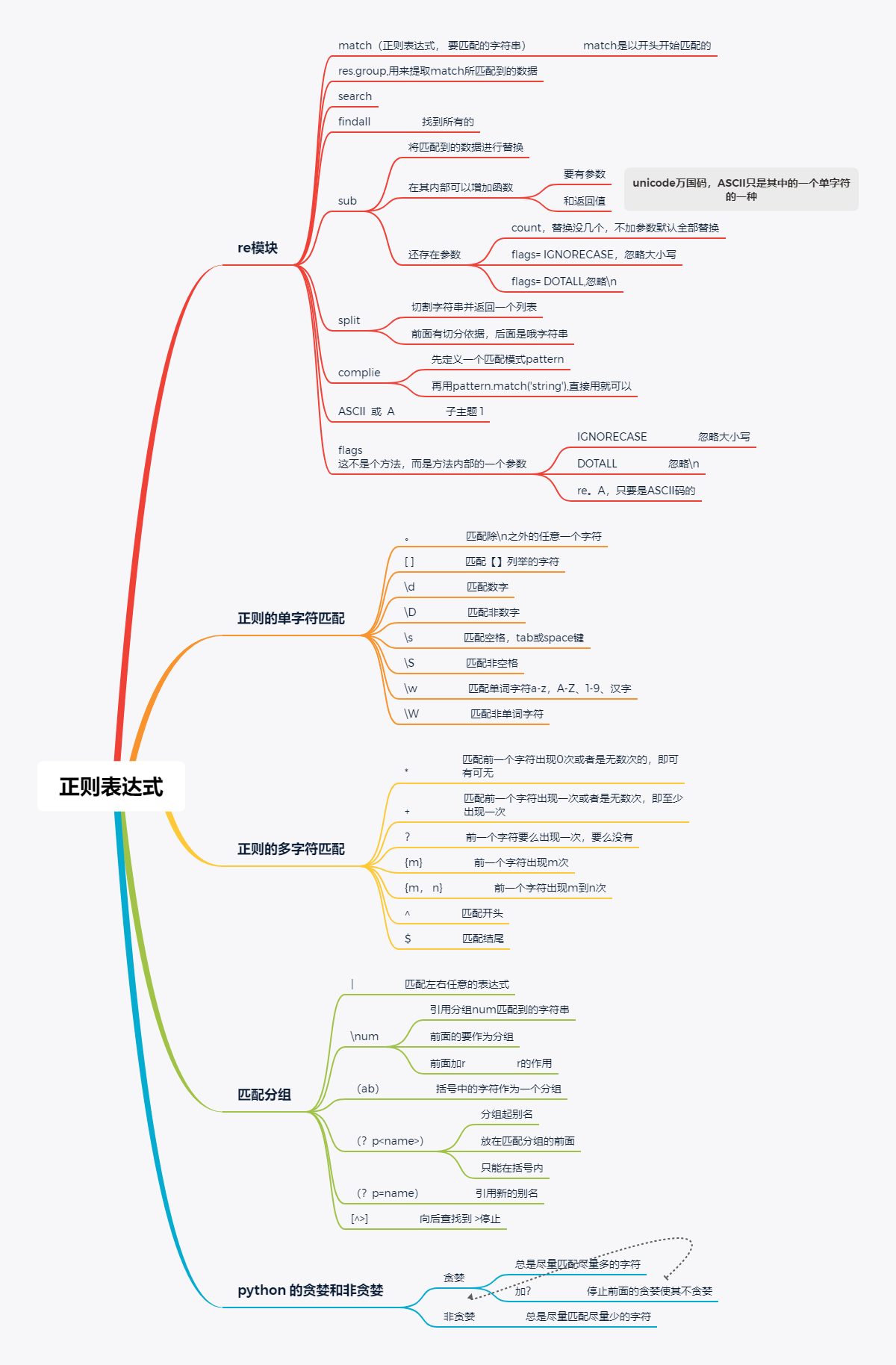
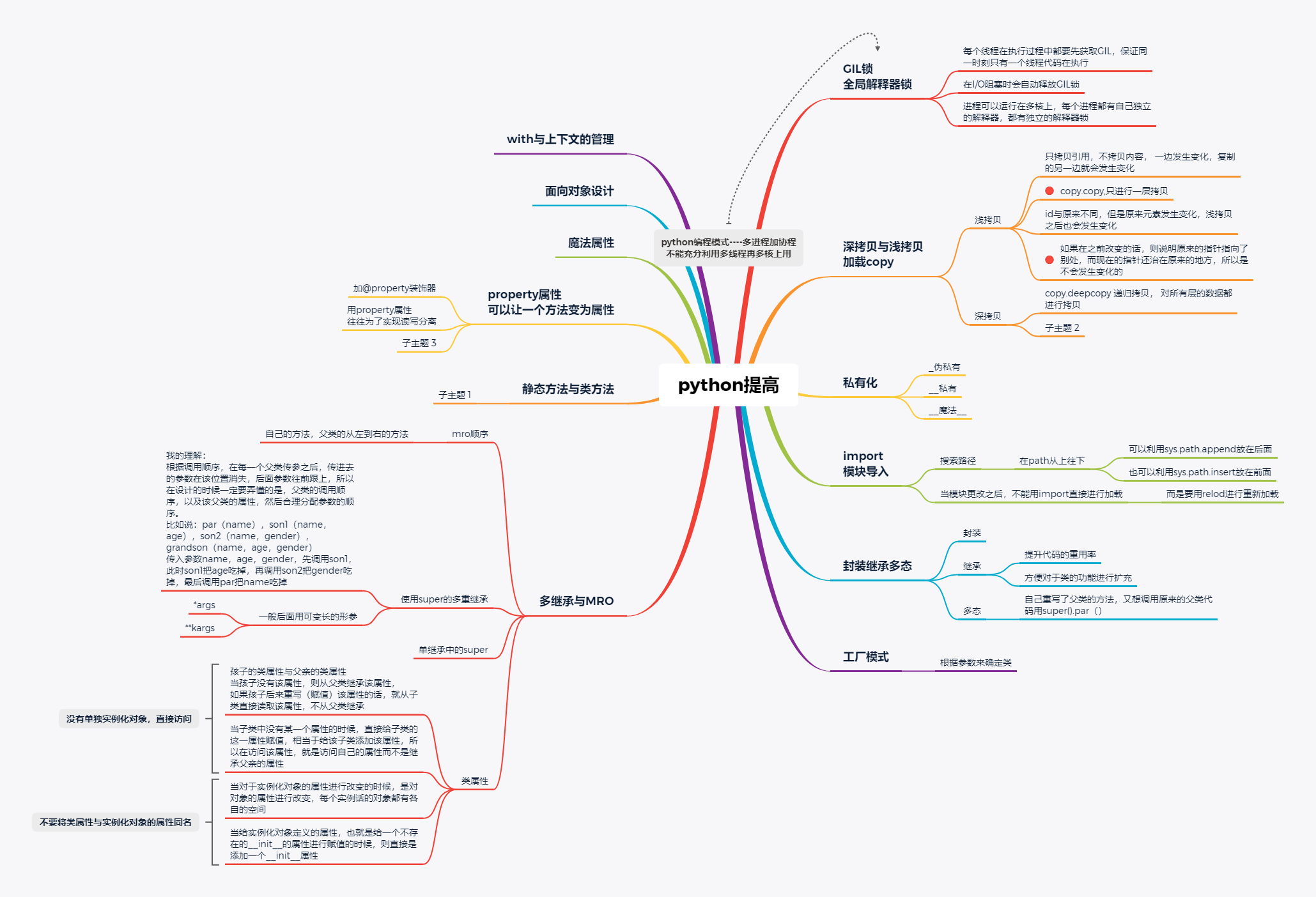
今天主要是正则表达式的相关内容,一些题目和思维导图。
- 写一个正则表达式,使其能同时识别下面所有的字符串:’bat’,’bit’, ‘but’, ‘hat’, ‘hit’, ‘hut
1 | import re |
- 匹配由单个空格分隔的任意单词对,也就是姓和名
1 | import re |
- 匹配由单个逗号和单个空白符分隔的任何单词和单个字母,如姓氏的首字母
1 | import re |
- 匹配以“www”起始且以“.com”结尾的简单Web域名:例如,http://www.yahoo.com ,也支持其他域名,如.edu .net等
1 | import re |
- 匹配一行文字中的开头的字母内容
1 | import re |
- 匹配一行文字中的开头的数字内容
1 | import re |
- 只匹配包含字母和数字的行(只要那一行有字母和数字就匹配)
1 | import re |
- 提取每行中完整的年月日和时间字段
1 | import re |
- 将每行中的电子邮件地址替换为你自己的电子邮件地址
1 | import re |
- 匹配\home关键字:
1 | import re |
- 去除以下html文件中的标签,只显示文本信息。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | 岗位职责: 完成推荐算法、数据统计、接口、后台等服务器端相关工作 必备要求: 良好的自我驱动力和职业素养,工作积极主动、结果导向 技术要求: 1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式 2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架 3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种 4、掌握NoSQL、MQ,熟练使用对应技术解决方案 5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js 加分项: 大数据,数理统计,机器学习,sklearn,高性能,大并发。 |
|
|---|---|---|
1 | import re |
- 将以下网址提取出域名:
http://www.interoem.com/messageinfo.asp?id=35`
http://3995503.com/class/class09/news_show.asp?id=14
http://lib.wzmc.edu.cn/news/onews.asp?id=769
http://www.zy-ls.com/alfx.asp?newsid=377&id=6
http://www.fincm.com/newslist.asp?id=415
1 | import re |
- 提取出如下字符串中的单词:
| 1 | hello world ha ha |
|---|---|
1 | # 这道题猜测让练split? |
14、练习深copy和浅copy
1 | import copy |
15、理解import中的坑
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Ongeno's Blog!








