这一周主要做了
Java 基础学习
看了一篇硕士大论文
机器学习大作业的优化
Java 基础的学习 主要是跟着菜鸟教程的Java 将高级教程之前的一些简单知识进行了学习,对于Java的基本语法,基本运算,程序结构都已基本入门,但还需进行大量练习;对于文件操作以及面向对象都有了初步了解,对于面向对象的封装继承多态都有了进一步的认识。并且也根据其中所带的一些实例,进行了实践性的操作。当然也有很多东西没有细学,比如正则,日期时间这些,原因如下:1.我觉得正则这个东西比较通用,又比较容易忘,所以暂时没有看;2.时间这个方面,就目前需求来看自己还用不到,所以就没有看。
这篇硕士大论文比较早,是属于对于复杂网络演化一篇论文,但是对于目前的复杂网络的研究现状,一些主流的模型的优缺点进行了罗列,以及对于复杂网络研究的一些难点与重点进行了阐述,算是我入门复杂网络演化的第一篇文章。其中对于随机ER网络模型、HK网络模型、HK可调簇系数模型等做了详尽的介绍。从网络的度分布、集团度分布、簇系数以及平均路径长度的特性,对于现实网络进行阐述,比如现实网络所具有的度幂律分布的特性幂指数在2-3之间、低阶集团度的幂律分布,从平均路径长度而反映出的显示社会网络的小世界特性以及具有的社团特性与簇系数之间的关系。
阐述了构建接近真实社会网络时:随机与加速增长的重要性。以及过去模型所具有的一些优缺点,为阐述自己所作的创新,做铺垫。
本文是首先是对HK可调簇系数进行的改进,对其加入了加速增长的机制,这种加速增长是随着新节点的增多,节点可选的连边增多导致的一种机制。使得改进后的HK可调簇系数模型更加的贴近现实网络特性。改进后的低阶集团度分布符合幂律分布,并且产生了5阶集团度分布,为改进之前根本不会产生5阶及以上的集团。
本文第二个创新是融入了共同邻居驱动与加速增长。
首先对于共同邻居驱动网络演化的理论,铺垫了很多的实证实验基础。另外加速增长又是真实社会网络演化的一个非常重要的因素,所以将其进行了融合。主要是在连接的加速增长做了另外一种改变,是随着时间步的增长,其老节点之间会进行加速连接,有共同的邻居的相似性越大,连接的可能性就越大。
机器学习大作业的探索 将鼠标与键盘数据做了融合,对于鼠标的特征进行了进一步的挖掘,增加了鼠标移动的方向,使得数据在boosting上的表现比单独在鼠标进行预测的表现好了很多。说明模型的鲁棒性比单个数据特征强了很多。
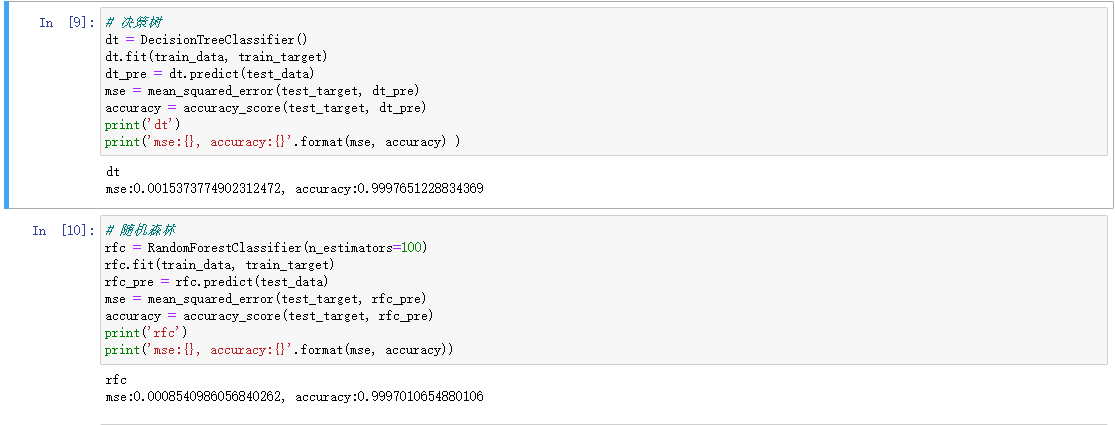
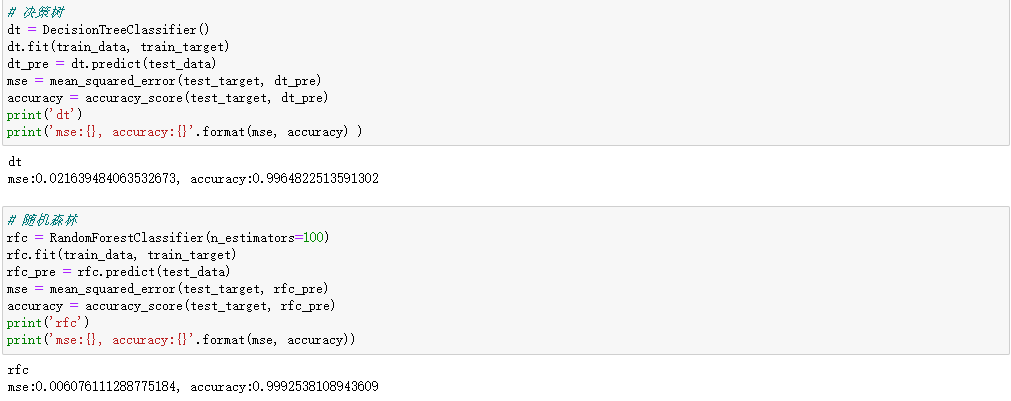
在决策树和随机森林已经达到了:99.9%
下一步准备:
周六下午及周日上午:
做了以上两个步骤,在多行合并的时候,脑子有些钝了,我想着是要对pd.DataFrame每五行取出来一行组成一个表,一共五个表,在进行横向的合并。
其实这个还是比较容易做到的,可是当时脑子不知道怎么钻了牛角尖,我就想到了循环抽取dataframe,就是硬写循环一个个抽出来再进行列向合并为一个表,之后进行行合并。结果显而易见,很费时间,就在跑着这个想法的时候,突然想到pandas.DataFrame可以进行切片,设置步长为5,啪的一声很快,五张表就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 // 抽取 n = 5 for i in range (n): locals ()["column" + str (i+1 )] = feature1[i:feature1.shape[0 ]:n] for i in range (n): print (locals ()["column" + str (i+1 )].shape) // 合并 for i in range (n): locals ()["column" + str (i+1 )].reset_index(drop=True , inplace=True ) featureConcat = pd.concat([column1, column2, column3, column4, column5], axis=1 ) featureConcat = featureConcat.dropna(axis=0 ) featureConcat.shape
对于鼠标数据的处理:
我丢弃了鼠标的绝大多数的数据,只是保留了,在鼠标里所作的具体的一些操作的名称。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def USBPreprocessing (filePath, newFilePath, csvPath ): file = open (filePath, encoding='utf-8' ) newfile = open (newFilePath, mode='w' , encoding='utf-8' ) counter = 0 for line in file.readlines(): if line.startswith('2019-0' ): print ("true" ) newfile.write(line) counter += 1 file.close() newfile.close() newFilePath = newFilePath newfile = open (newFilePath, mode='r' , encoding='utf-8' ) csvFilepath = csvPath csvfile = open (csvFilepath, mode='w' , encoding='utf-8' ) csvfile.write("Time" + '\t' + "USB" + '\n' ) for line in newfile.readlines(): x = line.split(sep=':' ) print (x) print () time = x[0 ] + ':' + x[1 ] + ':' + x[2 ] content = x[3 ] csvfile.write(time + '\t' + content + '\n' ) newfile.close() csvfile.close()
并将USB的特征加入了原有的特征中,进行处理,最终的结果如下:(Boosting还没跑完)
这里有些大意了,只用了mse(均方误差),可是实在是不想跑了。
最终的批量化处理函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.preprocessing import LabelEncoderdef mouseDirect (x,y ): res = 0 if x == y: res = 0 elif y > abs (x): res = 1 elif y > x and y < -x: res = 2 elif y < x and y < -x: res = 3 elif y < x and y > -x: res = 4 return res def featurePreprocessing (keyboardpath, mousepath, usbpath, label ): keyboard= pd.read_csv(keyboardpath) mouse = pd.read_csv(mousepath) usb = pd.read_csv(usbpath, sep='\t' ) keyboardDropCol = ['MessageName' , 'Window' , 'Ascii' , 'Key' , 'ScanCode' , 'Injected' , 'Alt' , 'Transition' ] keyboard = keyboard.drop(keyboardDropCol, axis=1 ) mouseDropCol = ['MessageName' , 'Window' , 'Injected' ] mouse = mouse.drop(mouseDropCol, axis=1 ) keyboard['keyboard' ] = 1 keyboard['mouse' ] = 0 mouse['mouse' ] = 1 mouse['keyboard' ] = 0 mouse['Position' ] = mouse['Position' ].map (lambda x: eval (x)) x = mouse['Position' ].map (lambda x: x[0 ]) y = mouse['Position' ].map (lambda x: x[1 ]) mouse['Position_x' ] = x mouse['Position_y' ] = y mouse = mouse.drop(['Position' ], axis=1 ) mouse['Direct' ] = 0 mouse_diff = mouse[['Position_x' , 'Position_y' ]] mouse_diff = mouse_diff.diff() a = map (mouseDirect, mouse_diff['Position_x' ], mouse_diff['Position_y' ]) mouse['Direct' ] = list (a) feature = pd.concat([mouse, keyboard,usb], axis=0 , ignore_index=True ) feature['Time' ] = pd.to_datetime(feature['Time' ]) feature = feature.sort_values(by='Time' ) feature['Time' ] = pd.to_numeric(feature['Time' ]) feature = feature.fillna(-100 ) encoder = LabelEncoder() feature['WindowName' ] = feature['WindowName' ].astype(str ) numeric = encoder.fit_transform(feature['WindowName' ].values) feature['WindowName' ] = numeric feature['USB' ] = feature['USB' ].astype(str ) numericUSB = encoder.fit_transform(feature['USB' ].values) feature['USB' ] = numericUSB column1 = feature[0 :feature.shape[0 ]:5 ] column2 = feature[1 :feature.shape[0 ]:5 ] column3 = feature[2 :feature.shape[0 ]:5 ] column4 = feature[3 :feature.shape[0 ]:5 ] column5 = feature[4 :feature.shape[0 ]:5 ] for i in range (5 ): locals ()["column" + str (i + 1 )].reset_index(drop=True , inplace=True ) featureConcat = pd.concat([column1, column2, column3, column4, column5], axis=1 ) featureConcat = featureConcat.dropna(axis=0 ) featureConcat['target' ] = label return featureConcat